
Intelligence artificielle et réseaux neuronaux
« Tenter de distiller l'intelligence dans une construction algorithmique peut s’avérer être le meilleur chemin pour comprendre le fonctionnement de nos esprits. »
— Demis Hassabis, Nature, 23 février 2012.
Comment l'IA pourrait réécrire l'histoire
Certains chercheurs vont devoir se recycler !
Du déchiffrement de rouleaux romains brûlés, à la lecture de tablettes cunéiformes en ruine, les réseaux neuronaux pourraient fournir aux chercheurs plus de données qu'ils n'en ont eu depuis des siècles.

L'IA tient plus que ses problèmes dans le domaine scientifique ; elle révolutionne aussi d'autres disciplines à une vitesse époustouflante, désorientant même certains chercheurs qui vont devoir très vite évoluer... ou disparaître.
C'est le cas de l'histoire.
Le projet, baptisé Vesuvius Challenge présenté par la revue Nature ce 30 décembre 2024, en porte témoignage : il s'agit ni plus ni moins que de ressusciter une ancienne bibliothèque à partir des cendres d'un volcan.
En octobre 2023, Federica Nicolardi, une papyrologue de l’Université de Naples en Italie reçoit un fragment d'un rouleau de papyrus brûlé lors de l'éruption du Vésuve en 79 APRÈS J.-C.
Le rouleau calciné était l'un des centaines de rouleaux découverts dans les vestiges d'une luxueuse villa romaine à Herculeanum, près de Pompéi en Italie, au XVIIIe siècle. Au fil des siècles, les tentatives visant à séparer les couches fragiles et carbonisées des rouleaux ont échoué.
La preuve ultime de la capacité de l'IA à résoudre des problèmes monumentaux est peut-être le succès des chercheurs qui étudient ces manuscrits d'Herculanum.
La lecture des rouleaux d'Herculanum pose deux problèmes majeurs.
Tout d'abord, ces rouleaux fragiles ne peuvent pas être déroulés. Pour voir à l'intérieur les chercheurs ont du inventer une nouvelle technologie qui consiste à prendre des tomodensitométries haute résolution de la structure interne d'un rouleau, à cartographier minutieusement à la main les surfaces visibles dans chaque image de la coupe transversale, puis à utiliser des algorithmes pour dérouler les surfaces en une image plate.
Ensuite, les scribes d'Herculanum ont utilisé de l'encre à base de carbone qui est invisible sur les scanners car elle a la même densité que le papyrus sur lequel elle repose.
Les chercheurs ont alors réalisé que même s'ils ne pouvaient pas voir l'encre directement, ils pourraient être capables de détecter sa forme. S'il y avait une différence subtile dans la texture de surface des fibres de papyrus nues par rapport à celles recouvertes d'encre, ils pourraient peut-être entraîner un réseau neuronal à repérer cette différence.
C'est alors qu'a été lancé le Vesuvius Challenge, qui offrait de gros prix en espèces. Ces images aplaties de surfaces de défilement ont été publiées, et il a été demandé aux participants d'entraîner des réseaux neuronaux pour les déchiffrer.
Plus de 1 000 équipes ont concouru, et des centaines de personnes ont discuté chaque jour des progrès sur le canal Discord du concours. Un grand prix a été décerné en février 2024 : les étudiants en informatique Youssef Nader, Luke Farritor et Julian Schilliger ont reçu ensemble 700 000 dollars pour avoir produit 16 colonnes de texte clairement lisible.

La reconstitution de textes anciens

Les réseaux neuronaux artificiels sont utilisés pour déchiffrer des textes anciens, des piliers classiques du grec et du latin à l’écriture osseuse de l’oracle chinois, des textes divinatoires anciens écrits sur des os de bovins et des carapaces de tortues.
Ils donnent un sens à des archives trop vastes pour être lues par des humains, remplissent des caractères manquants et illisibles et décodent des langues rares et perdues dont il ne reste pratiquement aucune trace.
Les résultats promettent une avalanche de nouveaux textes, offrant aux chercheurs plus de données qu’ils n’en ont eu depuis des siècles.
Mais ce n’est pas tout.
Parce que les outils d’IA peuvent reconnaître plus de langues et stocker plus d’informations que n’importe quelle personne ne peut en connaître – et découvrir par eux-mêmes des modèles statistiques dans les textes – ces technologies promettent une façon fondamentalement nouvelle d’explorer les sources anciennes.
Les réseaux neuronaux récurrents (RNN), conçus pour traiter des séquences de données dans lesquelles l’ordre linéaire compte, ont commencé à montrer un énorme potentiel pour rechercher, traduire et combler les lacunes dans des textes déjà transcrits. Ils ont été utilisés, par exemple, pour suggérer des caractères manquants dans des centaines de textes administratifs et juridiques formels de l’ancienne Babylone.
Les classicistes interprètent les nouvelles sources en utilisant leur connaissance de textes similaires existants. Ils sont généralement des spécialistes d'œuvres d'une époque et d'un lieu particuliers ; il n'est pas possible pour une seule personne de connaître toutes les sources potentiellement pertinentes pour un nouveau texte. C'est exactement le genre de défi que les modèles d'apprentissage automatique pourraient aider à relever.
Les chercheurs ont d'abord formé un modèle basé sur RNN appelé Pythia sur des dizaines de milliers d'inscriptions grecques écrites entre le VIIe siècle AVANT J.-C. et le Ve siècle APRÈS J.-C. Ils ont ensuite montré au modèle des textes qu'il n'avait pas vus auparavant et lui ont demandé de suggérer des mots ou des caractères manquants. Ils ont alors vu la restauration apparaître caractère par caractère à l'écran, ce qui n'avait jamais été possible auparavant.
En 2022, ils ont poursuivi avec un modèle appelé Ithaca, qui fait également des suggestions sur la date et le lieu d’origine d’un texte inconnu. Ithaca est disponible gratuitement en ligne et reçoit déjà des centaines de requêtes par semaine.
Ithaca atteint à elle seule une précision de 62 % lors de la restauration de textes endommagés.
Quand des historiens utilisent Ithaca, leurs performances passent de 25 % à 72 %, ce qui confirme l'impact de cette aide à la recherche synergique.
Ithaca peut attribuer des inscriptions à leur lieu de découverte d'origine avec une précision de 71 % et peut les dater à une distance de moins de 30 ans, redatant ainsi des textes clés de l'Athènes classique et contribuant aux débats d'actualité de l'histoire ancienne.
Ithaca associe Google DeepMind, l'Université d'Oxford, l'Université CA'Foscari de Venise (voir sur ce site Venice Time Machine), l'Université d'Athènes et Google Art et Culture.
De nombreux autres exemples pourraient être cités.
Katerina Papavassileiou de l’Université de Patras, en Grèce, et ses collègues ont ainsi utilisé un RNN pour restaurer le texte manquant d’une série de 1 100 tablettes mycéniennes de Knossos, en Crète, contenant des récits de troupeaux de moutons écrits dans une écriture appelée Linéaire B au deuxième millénaire AVANT J.-C dont on a très peu d'exemples.
Autant dire que c'est une quantité astronomique d'archives qui est maintenant à la disposition de chercheurs dont le métier a été complétement bouleversé en moins de 15 ans !
Prix Nobel de chimie 2024 pour les protéines
... et l'IA de Google !
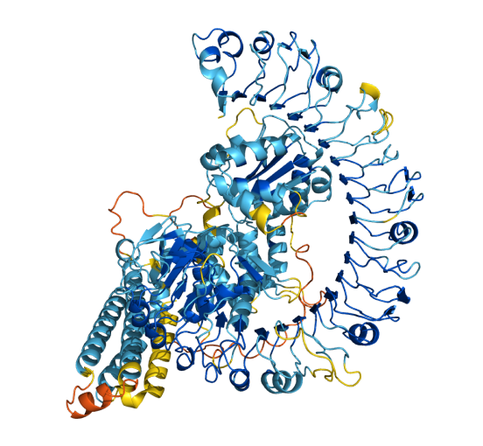
Le prix Nobel de chimie a été décerné mercredi à trois scientifiques pour des découvertes qui démontrent le potentiel des technologies avancées, notamment de l'intelligence artificielle.
Demis Hassabis et John Jumper de Google DeepMind, ont utilisé l'IA pour prédire la structure de millions de protéines ; et David Baker de l'Université de Washington, a utilisé un logiciel informatique pour inventer une nouvelle protéine.
Les docteurs Hassabis et Jumper faisaient partie d’une équipe de Google DeepMind, le laboratoire central d’intelligence artificielle de l’entreprise, et ont travaillé à une meilleure compréhension des structures des protéines.
Grâce à leur mode d’intelligence artificielle, AlphaFold2, ils ont finalement pu calculer la structure de toutes les protéines humaines, a déclaré le comité Nobel. Les chercheurs « ont également prédit la structure de la quasi-totalité des 200 millions de protéines que les chercheurs ont découvertes jusqu’à présent lors de la cartographie des organismes terrestres »
J'avais déjà parlé de leur travail ICI, en 2021.
Après le prix Nobel de physique, c'est le deuxième Nobel 2024 à impliquer l'intelligence artificielle, soulignant -si c'etait encore nécessaire - l'importance croissante de cette technologie dans la recherche scientifique.
L'étape suivante est déjà en marche !
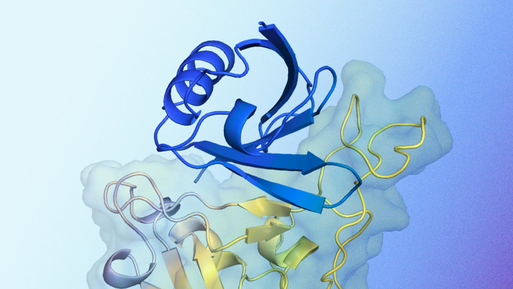
Grâce à AlphaFold, DeepMind a franchi un cap important en prédisant la structure des protéines.
Pourtant, cela restait insuffisant. D’où la création d’AlphaProteo.
Cette IA va plus loin : elle crée de nouvelles protéines capables de se lier à des molécules cibles spécifiques, comme le VEGF-A, une protéine facteur de croissance de l’endothélium vasculaire, impliquée dans le développement des cancers.
Étant donné ses capacités, AlphaProteo pourrait accélérer la recherche sur de nombreuses maladies. Selon les experts, elle représente un bond technologique majeur.
En effet, en termes d’innovation, cette IA ouvre des perspectives que l’on croyait impossibles il y a encore quelques années. Ses protéines sur-mesure offrent des perspectives impressionnantes, dépassant largement les méthodes traditionnelles.
AlphaProteo, est le premier système d’IA permettant de concevoir de nouveaux liants protéiques à haute résistance destinés à servir de base à la recherche biologique et sanitaire. Cette technologie a le potentiel d’accélérer notre compréhension des processus biologiques et de contribuer à la découverte de nouveaux médicaments, au développement de biocapteurs et bien plus encore.
Alors que le cancer continue de représenter un grand défi, AlphaProteo pourrait bien être la clé tant attendue. En clair, cette IA permet aux chercheurs de créer des liants protéiques ultra-précis. Ces liants fonctionnent comme un puzzle qui s’assemble parfaitement.
Par exemple, pour la protéine virale BHRF1, AlphaProteo a montré un taux de réussite de 88 % lors des tests. Ces chiffres sont impressionnants et laissent entrevoir des possibilités infinies.
Autrement dit, AlphaProteo permet de produire des protéines capables de bloquer certaines interactions cellulaires responsables de maladies. Dans le but d’améliorer les traitements contre le cancer, cette IA pourrait jouer un rôle crucial.
Entre autres, elle a été testée sur plusieurs protéines cibles liées au cancer, mais aussi sur des infections virales, comme le SARS-CoV-2. Ses résultats sont tout simplement bluffants.

L'IA, une révolution scientifique en marche...
... seule capable de traiter et de comprendre l'avalanche de données


Dans tous les domaines scientifiques les chercheurs croulent sous les données, par exemple :
-en biologie avec le décryptage du génome, du protéome, du microbiome, du métabolome...
- en astronomie où les données recueillies se chiffrent en petabytes,
- dans les sciences sociales où l'analyse des données fournies par internet (Google traite des dizaines de pétaoctets par jour !) est devenu un véritable casse-tête.
- en médecine avec l'émergence du patient numérique,
- en chimie organique, où le traitement informatique traditionnel a largement échoué dans l'accompagnement des synthèses multi-étapes complexes,
...
Un ordinateur de grande capacité est capable de trier des données, mais sur un énorme échantillon il n'en dégagera pas la substantifique moelle ; surtout pour des systèmes complexes, difficiles à modéliser à l’aide des méthodes statistiques classiques, ou dans toutes les situations où il existe une relation non linéaire entre une variable prédictive et une variable prédite.
Pour cela les chercheurs, s'inspirant du fonctionnement du cerveau humain, ont imaginé des réseaux de neurones artificiels.
Les réseaux neuronaux sont capables de détecter les interactions multiples non linéaires parmi une série de variables d’entrée, ils peuvent donc gérer des relations complexes entre les différents types de variables.
Ces réseaux sont composés de plusieurs couches de cellules reliées entre elles et formant une vaste toile. Un ensemble d'unités reçoit des éléments d'une entrée (par exemple des pixels pour une photo), effectue des calculs simples sur ces données, les transmet à la couche suivante et ainsi de suite. La dernière couche donne le résultat. Ce réseau est capable d'ajuster ses propres interconnexions, exactement comme cela se passe dans le cerveau humain lors de l'apprentissage.... Toute proportion gardée bien entendu (un réseau neuronal ne pourra pas à la fois conduire une voiture et faire une traduction, par exemple !).
En multipliant les couches, on aboutira à des modèles de plus en plus élaborés, on parle d'apprentissage profond (deep learning).
Il faut noter que Google est en pointe dans le domaine de l'IA, il développe par exemple une boite à outils de logiciels open source (Tensorflow).
Ces réseaux n'ont pas besoin d'être programmés ; ils apprennent seuls sur des modèles de plus en plus volumineux et complexes jusqu'à traiter des problèmes qui dépassent l'entendement humain ou qui nécessiteraient des temps d'analyse rédhibitoires.
Les résultats spectaculaires de l'IA dans le domaine scientifique se multiplient. Par exemple :
L' équipe de Martin Seligman (Université de Pennsylvanie) a prédit les taux de mortalité par maladie cardiaque au niveau d'un comté américain en analysant 148 millions de tweets !
Marwin HS Segler et al. utilise des réseaux récurrents de neurones comme générateurs de structures moléculaires dans la synthèse de médicaments de novo et obtient des résultats particulièrement prometteurs...
LIRE ceci : AI is changing how we do science.
Synthèse chimique et AI
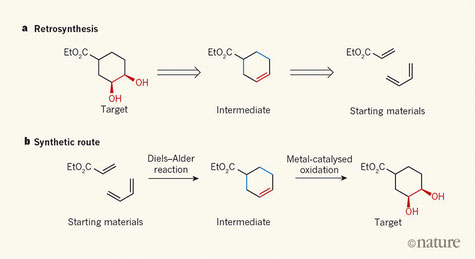
La chimie organique de synthèse consiste à élaborer des structures complexes à partir de briques élémentaires, en utilisant comme outil un ensemble de réactions chimiques rapportées par la littérature. Une sorte de bible des chimistes constamment enrichie, aujourd'hui constituée de milliers de références.
Depuis EJ Corey (Nobel de chimie 1990) et les années 60, le chimiste organicien a appris à rationaliser son travail en utilisant notamment une méthode rétrosynthétique, permettant de proposer des voies de synthèse raisonnables et optimisées.
A partir des années 80, l'informatique est venue aider le chercheur dans le débroussaillage du maquis des réactions chimiques applicables à la transformation d'un élément de structure moléculaire X en élément Y. Hélas, souvent ledit chercheur se trouve découragé par le nombre de solutions proposées.
Pourquoi ?
Tout simplement parce que la réaction chimique A qui permet de passer de X à Y est dépendante du contexte, c'est à dire des éléments de de structure Z, Z', Z'', ... qui sont également présents sur la molécule de départ, mais aussi des conditions opératoires (pH, température...), des problèmes stéréochimiques....
Pour chaque étape d'une synthèse, en gros, trois possibilités sont donc ouvertes :
- la réaction A peut s'appliquer directement,
- la réaction A pourra s'appliquer en masquant un élément Z, plusieurs éléments Z ou tous les éléments Z.
- la réaction A est inapplicable.
Ceci pour une seule étape... on imagine la difficulté quand on a affaire à une synthèse multistade qui comporte une dizaine d'étapes...
Les bases de données sont donc très utiles pour le chimiste, mais incapables de résoudre les équations à x dimensions et p paramètres, nécessaire aujourd'hui pour la réalisation d'une synthèse chimique.
(Même si quelques très lourds programmes sont maintenant proposés).

Photo JPL traitée par Deep Dream de Google, façon Van Gogh
Faut-il avoir peur de l'IA ?

Le développement de l'intelligence artificielle accompagne les progrès faramineux de la robotique. Pour l'instant nous sommes encore loin des humanoïdes de science-fiction, capables de séduire une belle terrienne, mais les premiers pas sont édifiants.
Par exemple le robot Atlas d'Alphabet (Google), grâce à une vision stéréo sophistiquée et de multiples capteurs, a la possibilité de manipuler des objets dans son environnement et de se déplacer sur un terrain accidenté.
Plus généralement, il me semble clair que la révolution de l'IA nous conduit vers une société transhumaniste, où raison, science et technologie pourraient être déployées au service de la lutte contre la pauvreté, la maladie, le handicap et la faim dans le monde,
Cette approche fait peur car elle implique le dépassement des limitations biologiques et la prise de contrôle de leur évolution par les humains eux-mêmes.
Pourtant les progrès scientifiques et technologiques, boostés par l'IA, indiquent que dans moins de 50 ans l'humain augmenté sera parmi nous.
Faut-il le craindre ? Personnellement je partage le point de vue du célèbre auteur de science-fiction Isaac Asimov :
“I could not bring myself to believe that if knowledge presented danger, the solution was ignorance."
Je n'ai jamais crû que si la connaissance présentait un danger, la solution était l'ignorance
NOTE : 2 000 signataires, dont Elon Musk, patron de SpaceX, Tesla..., ont adopté un guide de référence pour un développement éthique de l'intelligence artificielle. Ces « 23 principes d'Asilomar » s'inspirent un peu des 3 lois de la robotique de l'écrivain Isaac Asimov.

Aujourd'hui, en réalité, le risque majeur de la robotisation est une perte massive d'emplois peu qualifiés.
Les chiffres sont contradictoires. En France, le Conseil d'Orientation pour l'Emploi (COE, rattaché au premier ministre) estime à moins de 10% les postes de travail directement menacés aujourd'hui par l'automatisation (agents d'entretien, ouvriers qualifiés des industries de process, ouvriers non qualifiés de la manutention en tête).
D'autres publications sont beaucoup plus inquiétantes.
Une étude très pointue, réalisée à Oxford en 2013, indique que la part des emplois impactée par les évolutions technologiques pourrait varier entre 45 et 60% dans les états membres de l’Union Européenne. En France, le risque est estimé à 49,54%
En France UN emploi sur DEUX sera à court ou moyen terme menacé par cette révolution technologique.
Or nos systèmes publics d’éducation et de formation -initiale et continue- ne sont clairement pas adaptés à la mutation en cours.
Il est urgent de revoir l'organisation et le contenu des études dans notre pays, si l'on veut compenser, au moins en partie, la perte de plusieurs millions d'emplois dans les 10 ans à venir.
Exemples de robotisation en cours de développement :
* Une étude , menée par l'Organisation internationale du travail, indique que jusqu'à 137 millions de travailleurs à travers le Cambodge, l'Indonésie, les Philippines, la Thaïlande et le Vietnam - environ 56% de la main-d'œuvre totale de ces pays - risquent d'être remplacés par des robots, en particulier les travailleurs de l'industrie manufacturière du vêtement.
** Un robot australien est capable de construire un mur de briques 10 fois plus vite qu'un maçon.
*** Un fabricant suédois a conçu une trayeuse qui propose ses services aux vaches selon leur désir !
LIRE : Robots will destroy our jobs – and we're not ready for it
Robotique et neurosciences
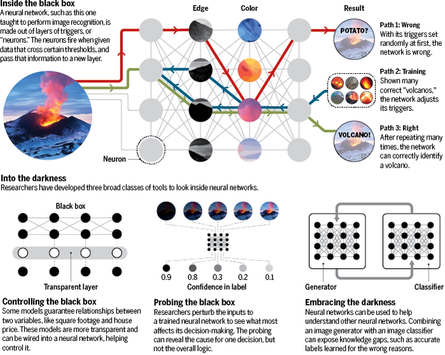
Voila qui ne va pas rassurer les populations frileuses devant les avancées de la science : on sait élaborer des réseaux neuronaux... mais on ne sait pas comment ils fonctionnent. Une vraie boite noire !
Comment comprendre que puisse être identifiée la forme d'un visage par une machine que l'on a gavée d'images d'objets hétéroclites ???
Il était donc urgent qu'émergent les neurosciences de l'intelligence artificielle !
Actuellement on développe des outils pour pénétrer l'esprit de la machine et donc l'améliorer. Les chercheurs rivalisent d'astuces et même de pièges pour craquer ces boites noires.
LIRE : How AI detectives are cracking open the black box of deep learning
Et si la recherche était totalement robotisée ?

Et si l'IA conduisait à la perte de nos jobs de chercheurs ?!
Dans la revue Science, John Bohannon qui décrit sa visite dans l'entreprise Zymergen à Emeryville (Californie), se pose la question.
Ce laboratoire de biotechnologie utilise toute une série de robots à vocation multiples pour, in fine, produire des "microbes" susceptibles d'intervenir dans la production de biocarburants, plastiques ou médicaments.
Ce type de laboratoire est courant, ce qui l'est moins c'est la façon dont la manipulation génétique est conduite à Zymergen où " ... pour interpréter des données, produire des hypothèses et planifier des expériences, le but suprême doit-être de se débarrasser de l'intuition humaine ", donc d'utiliser des robots intelligents. Faire du criblage à haut débit contrôlé par l'IA en quelque sorte.
Heureusement ce travail ne concerne qu'une petite partie des recherches dans cette interface chimie-biologie moléculaire-microbiologie-informatique (la fermentation microbienne en chimie "pèse" quand même 160 milliards de dollars !), car il est frustrant de ne pas comprendre "comment ça marche" !
Avant de conduire, dans de longues années, à la déshumanisation des laboratoires, l'IA peut au contraire apporter une aide très précieuse au chercheur, à tous les niveaux, de l'idée à la réalisation et à la publication des résultats :
- en triant de façon pertinente une bibliographie qui peut représenter des centaines voire des milliers d'articles,
- en suggérant des pistes de recherche,
- en proposant des protocoles expérimentaux,
- en pilotant des robots pour exécuter des tâches répétitives,
- en compilant et confrontant les résultats du laboratoire de toute nature...
...mais, pour l'instant, sans bannir l'intuition humaine, qui reste à la base des découvertes les plus innovantes.
L'apprentissage automatique
Pour résumer brièvement ce qu'est l'apprentissage machine on peut citer Arthur Samuel : «[l'apprentissage de la machine est le] champ d'étude qui donne aux ordinateurs la capacité d'apprendre sans être explicitement programmé".
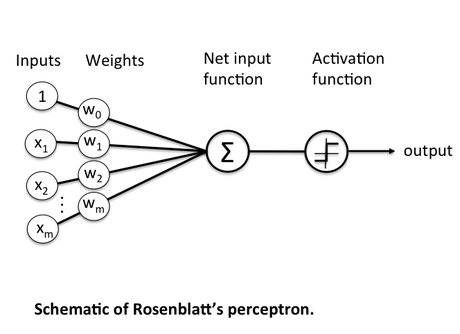
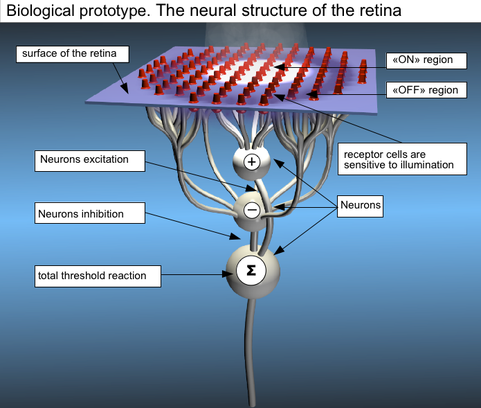
L'origine de la création d'un réseau neuronal artificiel tient à l'analogie de fonctionnement d'un neurone (ci-dessous, à gauche) et d'un perceptron (à droite).
Un neurone biologique peut être considéré comme la sous - unité d'un réseau de neurones dans le cerveau. Des signaux de grandeurs variables arrivent aux dendrites. Ces signaux d'entrée sont ensuite accumulées dans le corps cellulaire du neurone. Si le signal résultant atteint un certain seuil, un signal de sortie est généré qui sera transmis par l'axone.
Avec le perceptron de Frank Rosenblatt (1957), il s'agit de trouver un algorithme déterminant les poids respectifs de signaux d'entrée pour aboutir à une fonction capable ou non de générer un signal. C'était un système mono-couche qui n'avait qu'une seule sortie à laquelle toutes les entrées étaient connectées.
Un quart de siècle plus tard on introduira la Rétro propagation (Rumelhart, Parker, Le Cun, 1985) c'est à dire de la "convergence d’un algorithme itératif d’adaptation des poids d’un réseau de neurones multi-couche" pour en venir à une théorie de l'apprentissage (Support Vector Machine, Vapnik, 1992).
Pour aller plus loin sur l'analogie neurone biologique/neurone artificiel
Des puces neuro-inspirées

Le deep learning, comment ça fonctionne ?

Avant de décrire le deep learning, il faut parler de l'apprentissage supervisé, une technique permettant aux machines d'apprendre.
Il s'agit d'une technique d'apprentissage automatique, où l'on cherche à produire automatiquement des règles, à partir d'une base de données contenant des exemples déjà validés.
Par exemple pour qu'un programme apprenne à reconnaître une voiture, la base de données contiendra des milliers d'images de voitures, mentionnées comme telles.
Le deep learning utilise lui aussi l'apprentissage supervisé, mais la structure de la machine, composée de milliers d'unités de neurones artificiels, va permettre d'aller beaucoup plus "profond" dans l'apprentissage.
Pour reconnaître une personne, par exemple, la machine décompose l'image : d'abord le visage, les cheveux, la bouche, puis elle ira vers des propriétés de plus en plus fines (une cicatrice par exemple).
A chaque étape, le réseau de neurones approfondit sa compréhension de l'image avec une finesse accrue.
Sur l'image de gauche on voit le résultat en reconnaissance faciale avec quatre couches.
Le programme de deep learning de Google s'appelle "Google Brain", il est est lancé en 2011. Dès 2012 il conduit à un résultat spectaculaire : après avoir analysé dix millions de captures d'écran non étiquetées sur YouTube, la machine découvre par elle-même le concept de chat !
« Ce qui est remarquable, c'est que le système a découvert le concept de chat lui-même. Personne ne lui a jamais dit que c'était un chat. Ça a marqué un tournant dans le machine learning », Andrew Ng, fondateur du projet Google Brain.
Depuis, Google Brain s'est attaqué à bien d'autres sujets impliquant l'intelligence artificielle et les réseaux neuronaux, du véhicule sans conducteur au jeu de go. Il était donc tout naturel que Google l'utilise pour améliorer son outil Google Translate.
Neuron-Art by Google

Enfin, j'ai évoqué par ailleurs le programme «DeepDream », qui permet de visualiser un processus de deep learning, avec des résultats étonnants. Les formes repérées, analysées et interprétées dans une images ont visuellement « augmentées » par le programme.
" Si un nuage ressemble un peu à un oiseau, le réseau va le faire ressembler encore plus à un oiseau ".
Un travail surréaliste conduisant à des formes qui se situent entre le rêve, le mirage et l’hallucination psychédélique ... Un rêve de machine !
Pour générer vos propres rêves de machines, voyez ICI
Néanmoins, les progrès de l'intelligence artificielle donnent plutôt des cauchemars à certains. Google à déjà mis en place un bouton rouge pour freiner les délires de quelques uns. Aussi, un partenariat sur l'éthique vient d'être finalisé entre quelques géants du web.

Voici une photo personnelle en réalité augmentée selon DeepDream de Google
Google DeepMind : nouvel exploit à Londres


"Google DeepMind est une entreprise britannique spécialisée dans l'intelligence artificielle, appelée à sa création DeepMind Technologies, fondée en 2010 par Demis Hassabis, Mustafa Suleyman et Shane Legg, rachetée en 2014 par Google."
Le coeur de métier de l'entreprise est la mise au point de réseaux neuronaux artificiels que j'évoque ci-dessous.
Ces réseaux sont très performants dans les tâches qui impliquent la reconnaissance de formes, mais encore limités pour l'exécution d'instructions qui nécessitent une logique de base et un raisonnement complexe. C'est évidemment un souci pour le développement de l'intelligence artificielle (AI), qui doit permettre l'exécution de tâches complexes avec une supervision humaine minimale.

Les chercheurs avancent néanmoins à grand pas et la victoire de leur machine AlphaGo face grand maître sud-coréen Lee Se-Dol, qui domine le jeu de Go depuis une décennie, a fait récemment sensation.
La publication dans le journal Nature du 12 octobre 2016, montre qu'un nouveau pas vient d'être franchi.
Avec leur " Differentiable neural computer " (ordinateur neuronal différentiable), ils ont réalisé un système capable d'appréhender la navigation dans le métro de Londres, sans aucune information préalable, en résolvant toute une série d'énigmes logiques.
En gros cela revient à reconstituer un puzzle totalement inconnu, avec un très grand nombre de pièces, sans avoir été programmé pour cela.
La traduction by Google
L'application de traduction de Google, "Google Translate", est très perfectible ! Vous êtes nombreux à vous arracher les cheveux devant la bouillie de mots crachée par le traducteur, pour une simple version anglais-français.
Pourtant le géant de Mountain View n'a pas lésiné sur les moyens pour arriver à ce médiocre résultat : ce sont des centaines de millions de traductions professionnelles qui ont été ingurgitées par les ordinateurs pour leur apprentissage, plus de 20 milliards de mots traités.
Voir vidéo ci-dessous.

Google a donc décidé d'employer les grands moyens : les réseaux neuronaux artificiels, domaine de l'intelligence artificielle où il est particulièrement actif.
Le 27 septembre dernier, Google a annoncé la mise en place d'un nouvel algorithme, entièrement basé sur le "Deep Learning" (apprentissage en profondeur).
Pour l'instant le système est opérationnel pour l'anglais et le chinois, le français est en test. Le taux d'erreur a été réduit de 60%, il pourrait descendre à 85%, niveau des erreurs humaines !
L'intelligence artificielle restera-t'elle imprévisible ?
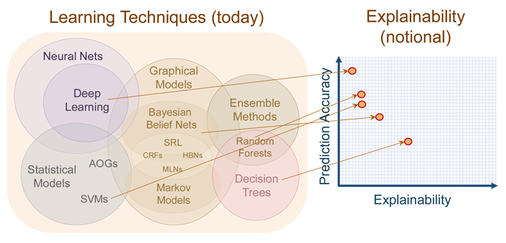
L'intelligence artificielle, basée sur les réseaux neuronaux, conduit à des résultats stupéfiants... parfois imprévisibles. Et cela fâche beaucoup de chercheurs !
En fait ils se trouvent devant un éprouvant paradoxe : plus on obtient les résultats souhaités... moins ont sait les expliquer.
La revue Nautilus traite de ce vrai problème au moment où ces réseaux neuronaux artificiels sont de plus en plus utilisés, notamment dans les services de santé. L'Union Européenne vient ainsi d'établir un «droit à l' explication» , qui permet aux citoyens d'exiger la transparence des décisions algorithmiques.